# 两种富集分析的理解
KEGG/GO 富集分析和 GSEA(基因集富集分析,Gene Set Enrichment Analysis)是两种不同但相关的分析方法,它们都有助于从基因表达数据中挖掘生物学意义,但它们的原理和使用场景有所不同。
# KEGG/GO 富集分析
KEGG/GO 富集分析是一种重要的基因功能注释和生物通路分析方法,通过统计学手段从基因列表中挖掘显著富集的功能注释(Gene Ontology, GO)或代谢通路(Kyoto Encyclopedia of Genes and Genomes, KEGG),以揭示基因表达变化的潜在生物学意义。
# 一些概念
# 基因功能注释(GO)
Gene Ontology(GO)是一套对基因及其产物的功能进行系统性描述的标准化术语,分为三个主要类别:
- 生物学过程(Biological Process, BP):基因参与的生物学事件(如 “细胞增殖” 或 “信号转导”)。
- 分子功能(Molecular Function, MF):基因产物的具体功能(如 “ATP 结合” 或 “转录因子活性”)。
- 细胞组分(Cellular Component, CC):基因产物在细胞内的位置或组成部分(如 “线粒体” 或 “核糖体”)。
# 代谢通路(KEGG)
KEGG 数据库提供了基因在代谢和信号通路中的注释和网络信息,涵盖多种生物学过程,如代谢途径、环境适应以及人类疾病相关的信号通路。通过 KEGG 富集分析,可以揭示基因的生物学背景及其在复杂网络中的作用。
# 背景基因集与目标基因集
- 背景基因集:在分析中定义的所有可能基因的集合(如全基因组或检测到的基因)。
- 目标基因集:研究中筛选出的特定基因列表(如差异表达基因,DEGs)。
# 核心方法:过表达分析(ORA)
# 什么是过表达分析?
过表达分析(Over-Representation Analysis, ORA)是一种统计方法,用于评估目标基因集中某些功能注释或通路的基因是否出现频率显著高于背景基因集。具体来说,它通过计算目标基因集中与某功能或通路相关的基因数量,与背景中的预期数量对比,确定是否显著富集。
# ORA 的基本步骤
- 首先定义一个目标基因集(如差异表达基因),从 GO 或 KEGG 数据库中检索基因的功能注释或通路信息。
- 使用超几何检验或 Fisher 精确检验,计算这些功能注释中观察到的基因数量是否显著高于随机期望值。
- 由于同时检测多个功能注释,需要进行校正(如 Benjamini-Hochberg 方法)以控制假阳性率。
# 举例
假设背景基因集中有 20,000 个基因,其中某条 KEGG 通路包含 50 个基因。在目标基因集(假设含 1,000 个基因)中,如果有 20 个基因属于该通路,则其富集程度可能高于随机预期(背景中比例为 50/20,000 = 0.0025,目标基因集比例为 20/1,000 = 0.02)。通过超几何检验和校正可以判断这种差异是否显著。
# 富集分析的生物学意义
# 揭示基因的功能背景
KEGG/GO 富集分析可以从基因功能注释和通路角度为目标基因提供更深层次的生物学背景。例如,某些显著通路可能与研究对象的生物学现象(如疾病或胁迫响应)直接相关。
# 提供研究线索
显著富集的通路或功能术语可以帮助研究者快速定位关键的生物学过程或调控机制,为后续实验设计提供假设。
# 定量评估通路的重要性
通过统计显著性评估(如 p 值或 FDR 校正值),富集分析为每个功能注释提供了可信度定量指标,便于研究者筛选和聚焦关键结果。
# KEGG/GO 富集分析的优缺点
-
快速功能注释。
-
依赖基因筛选阈值:只针对筛选出的目标基因,可能遗漏部分协同作用的基因。
-
忽略基因之间的表达方向:无法捕捉基因上调或下调的趋势。
# KEGG/GO 富集分析的应用场景
- 差异表达基因的功能注释:通过分析差异基因,挖掘特定条件下的显著功能或通路。
- 寻找疾病相关通路:识别与特定疾病(如癌症)相关的通路,为治疗研究提供靶点。
- 挖掘复杂生物学过程:揭示多基因调控的生物学机制。
# GSEA(Gene Set Enrichment Analysis)
GSEA(基因集富集分析)是一种基于整个基因表达谱的分析方法,通过对所有基因排序并评估预定义基因集(如功能注释或通路)在排名中的分布趋势,判断这些基因集是否表现出显著的协同上调或下调。GSEA 无需对基因表达设定显著性阈值,能够敏感地捕捉基因组层面的整体变化模式,特别适合分析微小但一致的调控趋势。
# 一些概念
# 基因集
GSEA 中的基因集是预定义的一组基因,通常根据其生物学功能、参与的信号通路或其他特定特性(如 GO 术语或 KEGG 通路)进行分类。例如,一个基因集可能包含所有参与 “细胞周期调控” 的基因。
# 基因排序
GSEA 的核心在于将整个基因表达数据排序,通常依据某种统计指标(如差异表达分析中 Fold Change),形成从最显著上调到最显著下调的基因排序。
# 富集分数(Enrichment Score, ES)
富集分数用于衡量基因集中基因在整个排序中的分布趋势。如果一个基因集中的基因倾向于聚集在基因排序的顶部或底部,则该基因集的富集分数较高,说明其可能具有生物学显著性。
# 核心方法
# 基因排序
根据基因表达差异的统计指标(如 Fold Change),对所有基因进行排序,形成从高到低的基因列表。
# 计算富集分数(ES)
针对每个基因集,沿排序基因列表逐步扫描:
- 如果扫描到的基因属于当前基因集,则增加富集分数。
- 如果扫描到的基因不属于基因集,则减少富集分数。
- 最终的富集分数是整个扫描过程中的最大偏离值,表示基因集中基因在排序中的富集趋势。
# 统计显著性评估
通过随机置换方法生成背景分布,比较实际富集分数与置换的随机分布,计算 p 值以评估显著性。
# 校正多重检验
针对多个基因集进行的分析,GSEA 通过 False Discovery Rate(FDR)校正来控制假阳性。
# 富集分析的生物学意义
- 揭示基因表达的整体趋势:GSEA 通过分析基因集的协同变化趋势,而非依赖单一基因的显著性,能够捕捉基因集整体的微弱调控模式。
- 避免显著性阈值的限制:传统方法需要设定显著性阈值筛选基因,而 GSEA 直接利用全基因表达数据,避免因阈值设定导致的信息丢失。
- 探索基因集的潜在功能:GSEA 不仅可以验证已知的功能基因集是否活跃,还能挖掘新的潜在基因集,从而揭示新的生物学机制。
# GSEA 的优缺点
-
不依赖基因显著性筛选,利用全基因表达数据,信息更全面。
-
能捕捉基因集的整体趋势,适合研究协同作用的基因集。
-
对基因排序方式较敏感,不同排序方法可能影响结果。
-
基因集中基因数量较少时,富集结果可能不稳定。
# GSEA 的应用场景
- 差异表达基因的趋势分析:在基因表达数据中,分析某些基因集(如通路或功能分类)的整体变化趋势。
- 疾病或表型的功能富集:研究与某种疾病或表型相关的基因集是否具有显著的调控趋势。
- 药物靶标发现:探索基因表达数据中潜在的药物靶标通路或功能。
- 复杂调控网络解析:通过基因集的富集分析揭示潜在的多基因调控机制。
# 主要区别
| 特点 | KEGG/GO 富集分析 | GSEA |
|---|---|---|
| 输入数据 | 差异表达基因列表 | 整个基因表达数据集 |
| 分析对象 | GO 术语、KEGG 通路中显著富集的基因 | 基因集在基因排名中的整体趋势 |
| 依赖基因筛选阈值 | 是(需要设定显著性阈值) | 否(基于全基因排序) |
| 应用场景 | 显著基因功能注释与通路分析 | 基因集整体的表达趋势分析 |
# 总结
两者有一定的互补性,适合不同的研究场景:
- KEGG/GO 富集分析适合快速分析显著基因的功能或通路。
- GSEA 适合挖掘基因表达谱的整体趋势,尤其是当单个基因的变化不显著但具有协同效应时。
# GSEA 的结果图怎么看
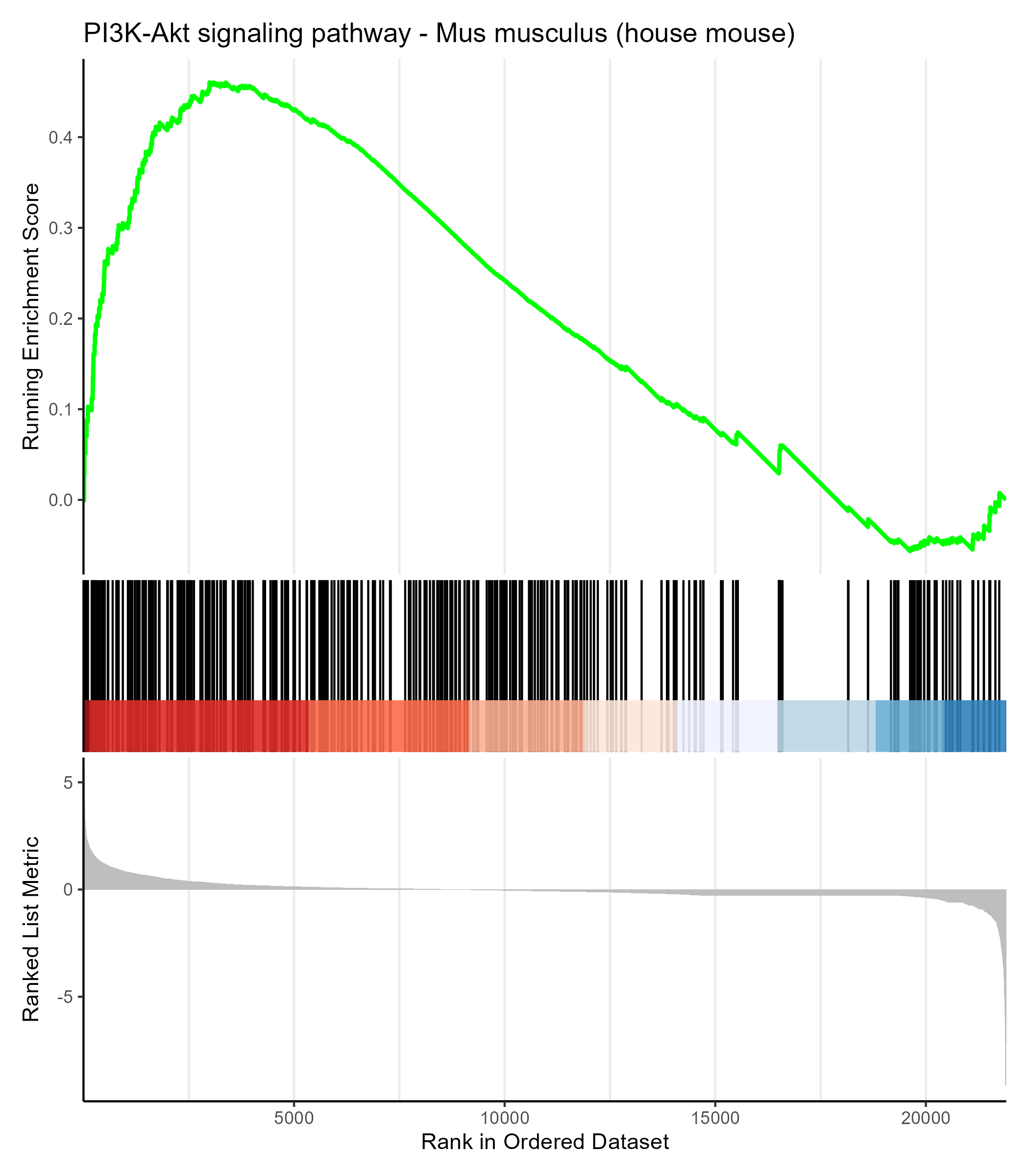
以上是一张典型的 GSEA(基因集富集分析)结果图,我们来解读一下:
# 图的标题
图的标题是 “PI3K-Akt signaling pathway - Mus musculus (house mouse)”,表明这张图是针对小鼠的 PI3K-Akt 信号通路基因集的 GSEA 分析结果。
# 上半部分:Running Enrichment Score
- 绿色曲线代表 “运行富集分数”(Running Enrichment Score, ES)的变化情况。
- 曲线通过沿着排序的基因列表逐步扫描基因集中的基因,计算 ES 得分。
- 曲线的最高点(即最大富集分数,Maximum ES)表示基因集在基因排名中的最强富集位置。
# 含义
- 如果曲线的峰值(最高点)出现在排序靠前的位置,说明该基因集的基因在上调基因中富集。
- 如果峰值出现在排序靠后的位置,说明该基因集的基因在下调基因中富集。
- 本图中,绿色曲线的峰值靠近排序前半部分,说明 PI3K-Akt 通路基因在上调基因中显著富集。
# 中间部分:基因位置的条形标记
# 含义
-
每一条垂直黑色线代表一个属于 PI3K-Akt 信号通路的基因在整个基因排序中的位置。
-
基因越集中在排序的前半部分或后半部分,说明富集越显著。
-
条形标记集中在排序的前段,进一步表明 PI3K-Akt 信号通路基因主要位于上调基因中。
# 下半部分:Ranked List Metric
# 含义
-
这是基因表达排序的统计指标(如差异表达的 Fold Change)。
-
左边值高(灰色柱状图较大)表示基因是上调的;右边值低表示基因是下调的。
-
本图中,灰色柱状图的左侧较高,说明上调基因在排序的前端,并且 PI3K-Akt 通路基因主要分布在这一部分。
# 富集分析的关键结果
# 富集分数(ES)和标准化富集分数(NES)
- 绿色曲线的峰值(最高点)代表最大富集分数(ES),用于衡量基因集在整个基因排序中的富集程度。
- 该图中没有显示 NES 值,NES 是 GSEA 中的一个关键指标,它是对 ES 进行标准化后的结果,旨在消除基因集大小和排列随机性对富集分数的影响,从而更具比较性和可靠性。
- NES > 0 表明基因集的基因倾向于出现在基因排名的顶部(通常与上调基因相关)。
- NES < 0 表明基因集的基因倾向于出现在基因排名的底部(通常与下调基因相关)。
# p 值 / FDR 校正值
- 这两个值没有在图中展示,但在 GSEA 结果中通常提供。
- 如果 p 值和 FDR 值显著(如 FDR < 0.25),说明该基因集的富集具有统计学意义。
# 总结解读此图
- PI3K-Akt 信号通路的基因主要富集在基因排序的前端,说明这些基因在上调基因中显著富集。
- 绿色曲线的峰值和条形标记的位置共同支持这一结果。
- 如果 p 值和 FDR 值显著,则可以进一步认为 PI3K-Akt 通路在当前条件下可能受到激活或显著调控。